PageIndex vs. Vector Databases
Why PageIndex Is a Superior Retrieval Architecture for Production AI
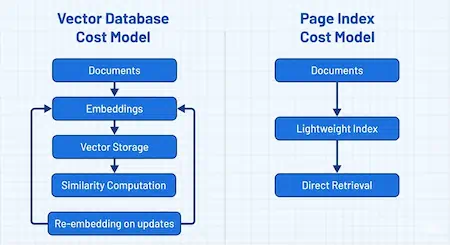
Vector databases have become the default retrieval layer for many Generative AI systems. They promise semantic understanding, flexible search, and fast prototyping. As a result, they are often treated as a mandatory component of modern AI stacks.
But as AI systems move from demos to mission-critical production workloads, a different reality emerges:
Semantic similarity alone is not enough.
For accuracy-driven, enterprise-grade AI applications, PageIndex-based retrieval offers a more reliable, explainable, and scalable foundation than vector databases.
The Core Problem with Vector Databases
Vector databases retrieve information based on numerical similarity in embedding space. While this works well for exploratory search, it introduces fundamental weaknesses when precision matters.
Vector-Based Retrieval Architecture